Project
This project has been funded by AES-ISCIII FIS20 (PI20/01305).
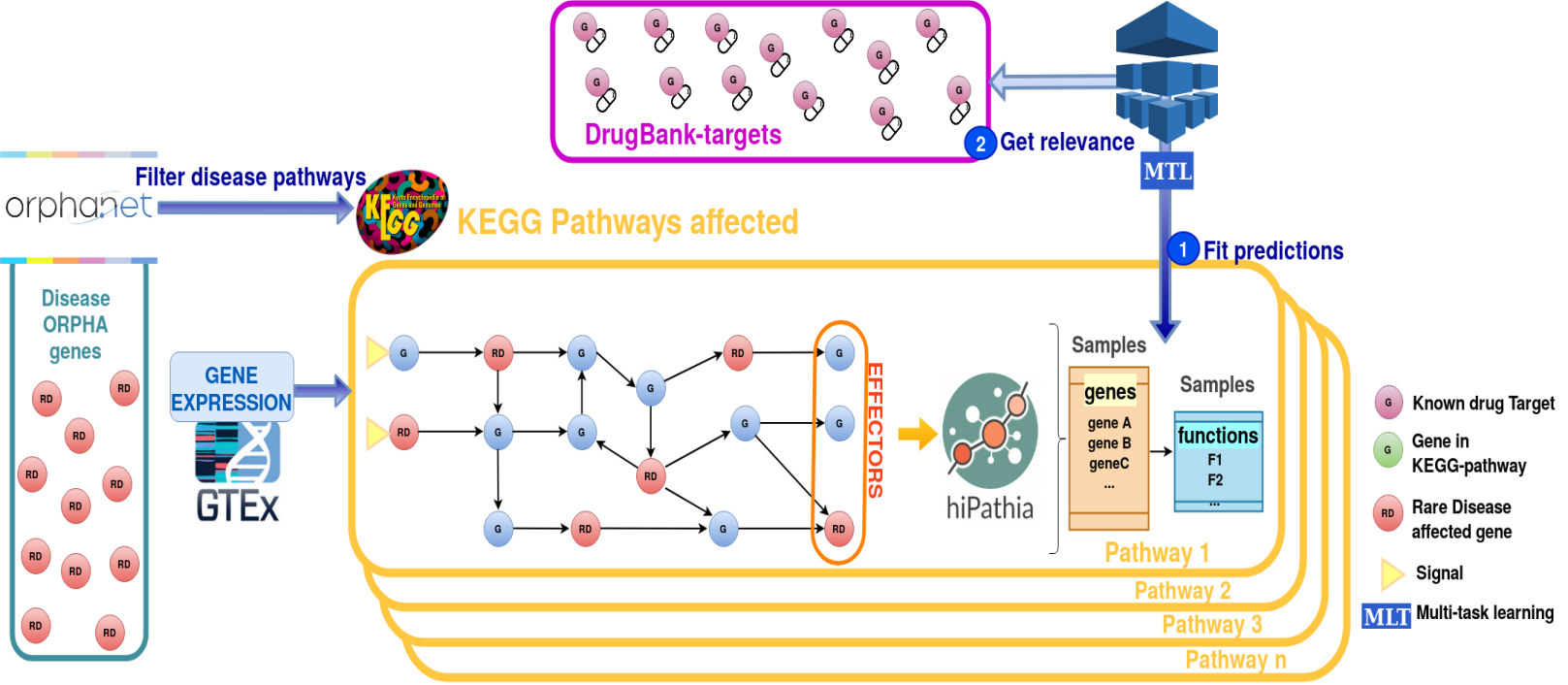
With the increasing trend of genomic data generation, machine learning (ML) methods are consolidating as ideal tools to extract new information from data repositories. An attractive opportunity for Big Data analysis is the possibility of extrapolate conclusions to fields in which little biological knowledge is available, i.e. Rare Diseases (RD). RD represent an important health challenge, despite their low incidence, given that the existence of over 6000 RD results in a total incidence of 6% of the population. Unfortunately, and because of the lack of resources dedicated to orphan drugs discovery, only 400 of them have an effective treatment. Thus, an interesting strategy to RD treatment discovery is the repurposing of drugs with indications already approved for other diseases. In this project we will systematically develop mathematical mechanistic models for rare neoplastic diseases that will be used to predict the effect of interventions, find potential therapeutic targets that revert disease or alleviate its symptoms and, among the targets found, select those that are already targets for known drugs. Information from signaling pathways, protein interactions and biological annotation will be integrated into a model to define functional outcomes of diseases and to connect other disease genes to them. ML methods will be used to extract potential genes’ relationships in order to build comprehensive disease maps. However, in spite of the abundance of genomic data, the number of variables to take into account is also high, to overcome this issue we will make use of variational approximations in genomics, which are less prone to overfit the data.